In a 2009 article published in AI Magazine, Jonathan Grudin describes Human-Computer Interaction (HCI) and Artificial Intelligence (AI) as "two fields divided by a common focus." He claims that HCI focuses on new technologies that promises widespread availability, while AI research also focuses on new technologies but with very limited availability due to expensive computing resources.
Today, the landscape looks dramatically different. The fruits of AI research has been made available to more members of the public thanks to advancements in hardware and software infrastructures for managing machine learning pipelines as well as distribution of AI resources via cloud computing. As AI interfaces more with people, HCI researchers are increasingly interested in leveraging new technological capabilities enabled by AI to develop novel interactive systems and studying the impact of AI on human behaviour. It seems inevitable, then, that the two fields overlap and converge (and will continue to do so) in interesting ways.
In this work, we explore the intersection of HCI and AI by examining the academic publications in each area. We embody the two fields by their flagship conferences: the ACM Conference CHI Conference on Human Factors in Computing Systems (CHI) for HCI, and the Conference on Neural Information Processing Systems (NeurIPS) for AI. Using works published at these two conferences for the past 20 years alongside modern NLP techiques, we aim to surface trends in the HCI-AI overlap and use those trends to unearth potential future research directions within this ever-growing intersection.
Related Work
Historical Relationships Between HCI and AI
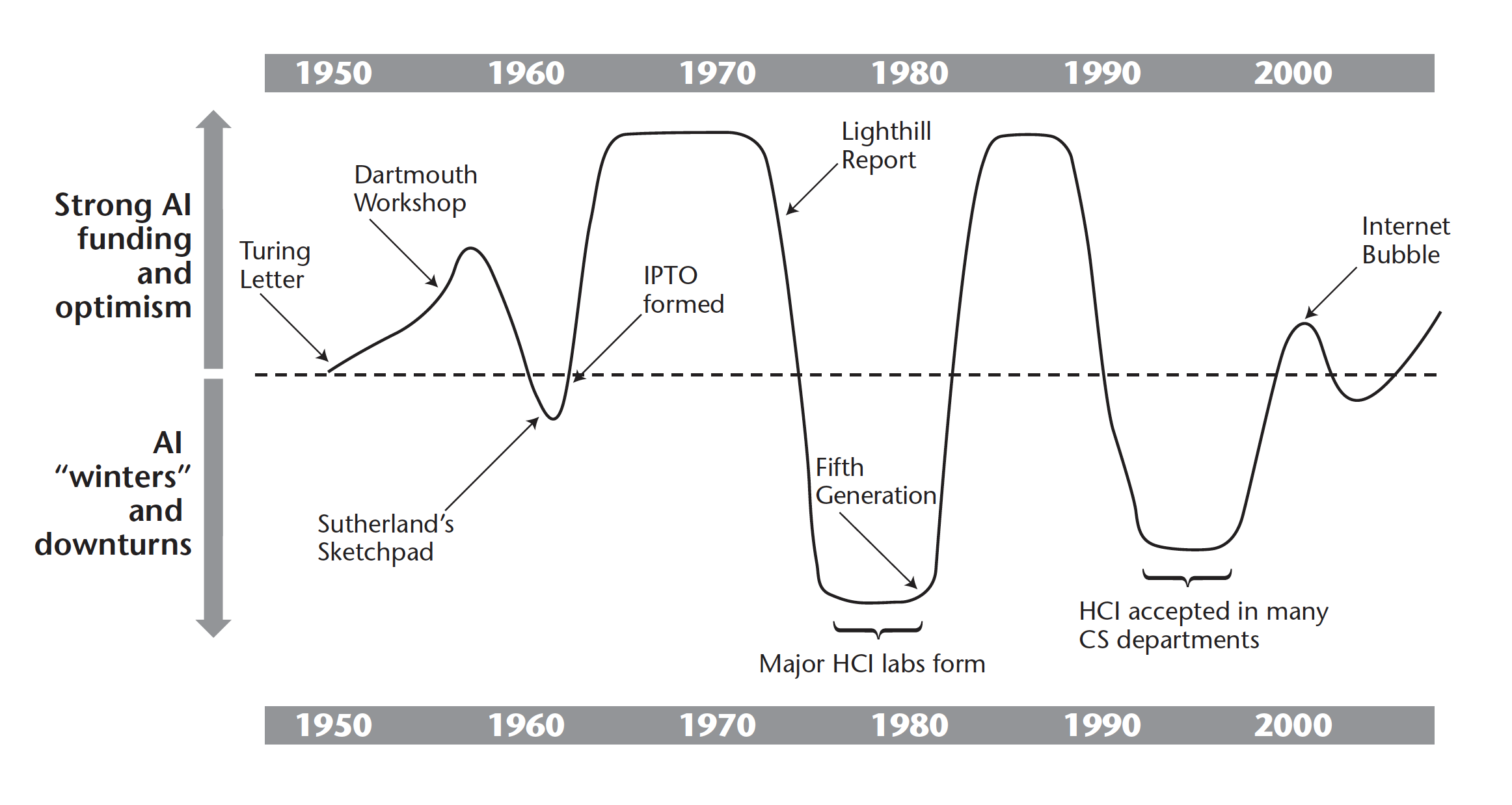
The rise in popularity of "usable AI"- and "human-AI interaction"-style conference events and workshops in recent years is strong convergence between HCI and AI. The convergence is mutual. For the 2nd year in a row, NeurIPS is hosting the Human-Centered AI workshop to bring together members of the NeurIPS and HCI communities to "explore research questions that stem from the increasingly wide-spread usage of machine learning algorithms across all areas of society" . CHI workshops have also been engaging with AI topics and practitoners, such as the 2019 workshop on "bridging the gap between AI and HCI (CHI 2019)" as well as one on "trust and reliance in humam-AI teams (CHI 2022)" . However, even before these events became popular, researchers have long been tracking the history of AI and HCI to find intersections. Grudin mapped out AI "summers" and "winters" starting in the 1950s and declared that HCI's greatest periods of development (most notably in the early 1980s when influential HCI labs formed at PARC, IBM, Bell Labs, and UCSD, among other places) corresponded with AI winters, when momentum behind AI research dwindled and so did funding. He posited that this was due to the two fields competing for common resources. However, we do not see strong evidence for the blistering pace of AI research today to take a toll on the growth of HCI; in fact, it's the opposite—HCI is enriched by new AI capabilities and limitations. We verify this observation through our analysis of HCI and AI publications.
Techniques for Analyzing Academic Papers
Researchers have previously attempted to identify research trends through historical analysis of conference publications. Liu et al. mapped 20 years of CHI publications from 1994 to 2013 via hierarchical cluster analysis, strategic visualizations, and network analysis and concluded that themes within HCI have become more cohesive, while the number of themes have simultaneously increased. They reasoned that external factors, such as the introduction of new technology, stimulates the development of new themes. They used the iPhone and Facebook as examples of new technology, so one can easily see how modern AI beakthroughs can fit the mould for an effective catalyst of new HCI work. In a 2018 blog post , the Microsoft Academic team presented a historical trend analytics of NeurIPS from 1996 to 2017 using the Microsoft Academic Graph. The post presented insights such as paper output over time, incoming and outgoing citations, top authors, and top institutions, but the analysis was constrained by metadata available in the graph.
Advancements in NLP techniques bring a new dimension to this style of analysis. Google introduced BERT in 2018 as a new pre-trained language representation model to be easily fine-tuned for a wide range of tasks. SciBERT was released by the Allen Institute for AI in 2019 as a BERT model fine-tuned on a large multi-domain corpus of scientific publications. SciBERT was shown to outperform BERT-Base on a variety of tasks datasets in scientific domains and displays potential in creating powerful embeddings to signal document-level relatedness. Indeed, a follow-up work introduces SPECTER , a citation-based method to generate unsupervised, document-level embeddings based on a pretrained transformer model (such as SciBERT). SPECTER embeddings for papers on Semantic Scholar are available through the Semantic Scholar Academic Graph API. Unsupervised embeddings have been shown to capture complex in scientific domains, such as materials science, where Tshitoyan et al. found that they can learn representations of underlying structures of the periodic table and structure–property relationships in materials . Additionally, Tshitoyan et al. demonstrated that the embeddings can also be used to recommend materials for real-world applications ahead their discovery. Although some findings are specific to material science, many can be generalized to knowledge extraction approaches for scientific domains beyond material science.
In our work, we leverage insights from previous work to conduct cross-disciplinary analysis of academic work to reveal new interdisciplinary research directions. Specifically, we use embeddings computed with SciBERT to identify relationships between papers published in CHI and NeurIPS and perform additional analysis to identify common trends and predict new ones.
Methodology
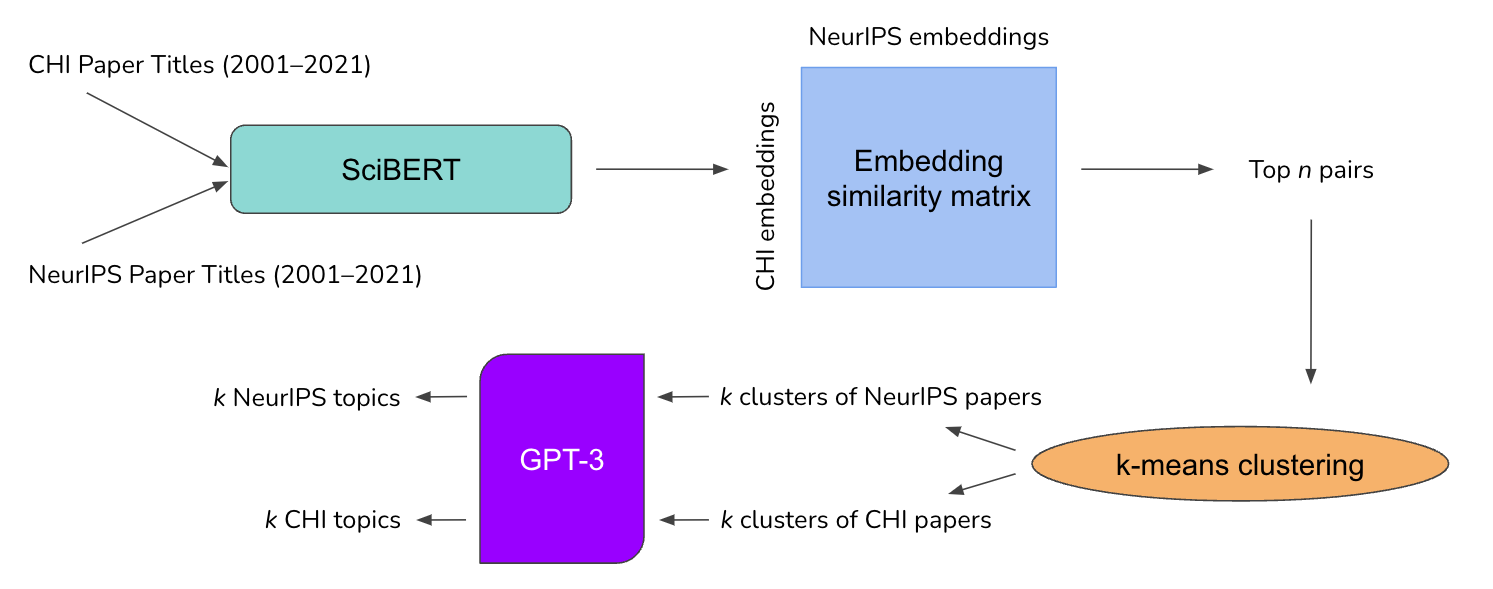
We sourced our papers from DBLP, a bibliography website for computer science literature. We chose DBLP over DOI, despite DOI being more prevalent among academic citation networks, due to its ability to search papers by venue. We scraped CHI and NeurIPS papers from DBLP published between 2001 and 2021, including only conference proceedings (as opposed to workshop papers) to keep our dataset to a manageable size for analysis on a GPU-constrained cloud environment. While we only scraped paper titles, we then used the Semantic Scholar (S2) API to query papers using our titles to obtaining richer information about each paper, including the abstract and SPECTER embeddings.
Once we had our dataset, we decided to compute our own embeddings as the SPECTER embeddings were not available for all papers in our dataset; 72.3% of papers across both conferences had them. To do so, we fed our paper titles into SciBERT to obtain a series of embeddings. We the computed an embedding similarity matrix with all combinations of papers via their respective conferences and years. We used cosine similarity as our similarity measurement. We then identify the top n most similar pairs as a filter to preserve literature that may lie close to or in the intersection of the two conferences. We then separate the filtered papers based in their conferences, obtaining a set of CHI papers that are similar to NeurIPS papers (as judged by their embeddings) and vice versa. We then perform k-means clustering within the pools of filtered papers in their respective conferences to look for topical similarities within each conference. With clusters of k papers from each of CHI and NeurIPS, we took the abstracts from those clusters and fed each abstract cluster into GPT-3 (text-davinci-003, temperature = 0.2) to obtain a keyphrase that summarizes the cluster, which we call the cluster's "topic". We then leverage our collection of AI-adjacent HCI topics and HCI-adjacent AI topics to propose future research directions at the intersection of AI and HCI.
Findings
We analyzed a total of 14,000 papers from CHI and NeurIPS published between 2001 and 2021. We set n = 100 and k = 4 to obtain clusters of reasonable quality after some experimentation. To provide an overview of our dataset, we plotted the number of publications in each conference against the year. As per Figure 3, the size of CHI grew consistently over the years whereas NeurIPS grew steadily until about 2016, from which it started experiencing much more rapid growth.
Upon computing embeddings, we plotted a heatmap of cosine similarity scores of abstracts from papers in our dataset, with a conference on each axis Figure 4. We notice that the gradation of color lies primarily along the y-axis. This means that the change in similarity over a longer-term span of CHI publications for a particular year of NeurIPS is typically greater than the reverse. The asymmetry indicates that NeurIPS has a greater influence on CHI than vice versa. That said, the slight gradation along the x-axis in more recent years of CHI indicates that HCI may exert an increasingly non-neglegible influence in AI. The accumulation of high similarity scores in the top right corner of the chart confirms the convergence of AI and HCI as indicated by previous, more qualitative analyses.
The asymmetry in HCI-AI influence is made even more obvious if we consider time slices of one conference with respect to the entire 20-year span of the other conference. If we select NeurIPS in the conference selector along with any year in Figure 5 and view the variation in cosine similarity with respect to 20 years of CHI, we will see a generally positive trend, meaning that CHI paper embeddings are becoming more similar to NeurIPS paper embeddings. On the other hand, if we select CHI with any year and view the variation in cosine similarity with respect to 20 years of NeurIPS, we will see a generally flat trend.
After obtaining our abstract clusters, we labelled each cluster with a topic by prompting GPT-3 (text-davinci-003, temperature = 0.2) to summarize the cluster into a keyphrase. Due to token limitations in our free trial of the OpenAI API, we chose to only label clusters published in the last 5 years (2017 to 2021). Even then, the output appeared to require some manual adjustment, so we filtered out any non-sensical topics. Select a combination of CHI and NeurIPS years in the table below to see their cluster topics.
| Conference | Year | Topic |
|---|
We also used a more classical approach to computing keywordsL TF-IDF. For this second table, we show the top TF-IDF feature for each conference/year cluster along with the number of abstracts containing that feature. Unlike with GPT-3, we were able to run this approach over the entire timespan of our dataset.
| Conference | Year | Topic | Number of Abstracts |
|---|
Discussion
Opportunities to Generate Novel Research Directions
Our analysis reveals that the intersection of AI and HCI has grown steadily over time. This presents opportunities to uncover new research directions at this intersection, but where should one start? Our interactive table above may aid this endeavour: by allowing mixing-and-matching topics from different conferences and years, users may find inspiration in the juxtaposition of topics. To take it a step farther, users may be interested in leveraging the generative capabilities of large language models to spawn new research ideas based on the topics in the table. Using ChatGPT, we found the following prompt structure to be effective in yielding an output that not only states a direction, but also elaborates on potential approaches and efficacy:
Generate a research direction for me given these topics:
1. {...}
2. {...}
3. {...}
{...}
Limitations and Future Work
One limitation of our work is that we generated embeddings of each paper by encoding only the abstracts. While the abstract summarizes the essence of the paper, it lacks the details of the methodologies, related works, and results of the work. Future work may consider generating embeddings based on the full text of the paper. With a better representation of the papers in the semantic space, we would be able to compute similarity of papers more precisely.
Another limitation is that when computing similarities, we only looked at the semantics of the papers (by encoding the abstracts). One additional relevant information that is not encoded in the text is the citation of the papers. Often, one would be able to tell if two papers are relevant by looking at their references. Including the citation information in the embedding would also help us find the intersecting papers of CHI and NeuRIPs papers. We considered using the SPECTER embeddings provided through the S2 API, but they were only available to a little under three-quarters of the papers in our dataset. Per the SPECTER GitHub repository, running SPECTER on our own machines will produce different results than those provided by the API due to differences in model versions. Future work may generate the SPECTER embeddings from scratch for standardization, and then use those embeddings for analysis.
Lastly, the topics generated using GPT-3 lack a rigorous evaluation for their faithfulness. While GPT-3 has shown to be a powerful language model, we still would like to verify if the topics generated reflect the semantics of the clusters of abstracts. Our evaluation method is to sample a small set of abstracts, and verify if the topics make sense. However, with this method, we do not know if the topics are faithful at scale. Thus, one compelling avenue for future work is to build a human-in-the-loop system for topic generation where a user can confirm or correct a generated title, as well as ask the model to explain its decision-making through a natural language interface such as ChatGPT.
Conclusion
We collected and analyzed over 14,000 abstracts from papers published at CHI and NeurIPS over the past 20 years (2001 to 2021) to investigate the growing intersection between the fields of AI and HCI. We computed embeddings on paper abstracts using SciBERT and filtered papers with similar cross-domain embeddings: CHI abstracts with a high similarity score to NeurIPS abstracts and vice versa. We found an asymmetry in similarity scores, with CHI abstracts noticeably approaching similarity with NeurIPS abstracts but not the other way around. This points to the field of AI as being a larger influence on HCI than HCI is to AI. Furthermore, we clustered our filtered papers and used GPT-3 to generate topic labels, which we can then view in different combinations throughout the 20-year time period. We discuss guidelines on how to use those topics to derive future research questions. We hope that this analysis can inspire researchers to pursue new and exciting directions at the intersection of AI and HCI.
Materials
Download our data (.zip)View our analyis code (Google Colab)